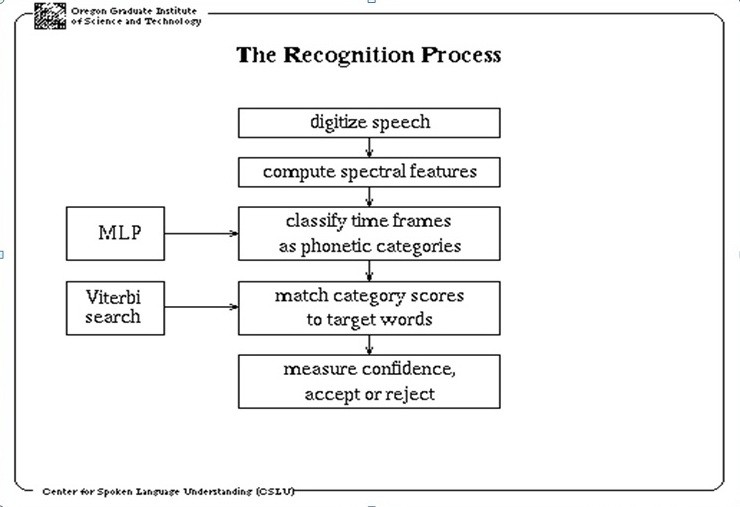
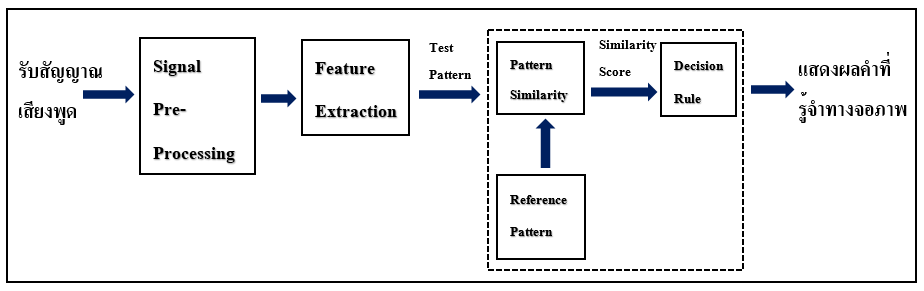
ทฤษฎีรู้จำเสียงพูด (Speech Recognition) ทฤษฎีรู้จำเสียงพูด (Speech Recognition) ทฤษฎีรู้จำเสียงพูด (Speech Recognition) คือระบบโปรแกรมคอมพิวเตอร์ที่สามารถแปลงเสียงพูด (Audio File) เป็นข้อความตัวอักษร (Text) โดยสามารถแจกแจงคำพูดต่าง ๆ ที่มนุษย์สามารถพูดใส่ไมโครโฟน โทรศัพท์หรืออุปกรณ์อื่น ๆ และเข้าใจคำศัพท์ทุกคำอย่างถูกต้องเกือบ 100% โดยเป็นอิสระจากขนาดของกลุ่มคำศัพท์ ความดังของเสียงและลักษณะการออกเสียงของผู้พูด โดยระบบจะรับฟังเสียงพูดและตัดสินใจว่าเสียงที่ได้ยินนั้นเป็นคำ ๆใด ทฤษฎีรู้จำเสียงพูด (Speech Recognition) เทคโนโลยีที่เป็นส่วนสำคัญในการทำ ASR เรียกว่า Hidden Markov Model (HMM) เทคโนโลยีชนิดนี้สามารถที่จะเข้าใจคำพูด จากการจำแนกความแตกต่างและการประมาณการถึงความเป็นไปได้ของส่วนประกอบของหน่วยที่เป็นพื้นฐานของเสียงที่อยู่ติดๆกัน โดยอาศัยหลักการที่ว่าเสียงแต่ละเสียงจะมีขอบเขตของสัญญาณและลักษณะเฉพาะที่มีความแตกต่างกัน โดยปกติในการสร้าง Speech Recognition จะมีขั้นตอนการปฏิบัติอยู่ทั้งหมด 4 ขั้นตอน ซึ่งจะพยายามอธิบายโดยสรุปได้ดังนี้ การทำงานของระบบ Speech Recognitionขั้นที่ 1 แปลงคลื่นเสียงที่มากระทบในขั้นต้นให้เป็นตัวเลขที่เราต้องการเพื่อทำความเข้าใจขั้นที่ 2 คำนวณถึงลักษณะเฉพาะซึ่งเป็นสัญลักษณ์ของ Spectral โดย domain ที่เป็นหัวเรื่องของ Speechลักษณะ เหล่านั้นจะถูกคำนวณทุกๆ 10 msec โดยแต่ละ10 msec จะถูกเรียกว่า “Frame“ขั้นที่ 3 Artificial Neural Network (ANN) แบบ Multi – Layer Perceptron (MLP) จะถูกใช้เพื่อแยกชั้นของกลุ่มของลักษณะเหล่านั้นไปสู่ phonetic-based categories ในแต่ละ frameขั้นที่ 4 Viterbi search จะทำการจับคู่ neural network output scores กับคำศัพท์ที่ต้องการ ทฤษฎีรู้จำเสียงพูด (Speech Recognition)Viterbi Search ใช้กำหนดถึงความต่อเนื่องของหน่วยพื้นฐานของเสียงจากความเป็นไปได้สูงสุด โดยคำนวณผ่าน Gaussian Mixture Model ข้อดีของ Viterbi Search คือการประมวลผลข้อมูลเป็นแบบ Real time แต่ข้อเสียคือระบบจะเลือกตัด Path ที่ Prob ต่ำเกินกว่ากำหนดไปและไม่นำกลับมาพิจารณาอีกเลย ทั้งๆ ที่บางครั้ง Path นั้นอาจจะมีค่าความน่าจะเป็นรวมสูงขึ้นกว่า Path อื่นเมื่อ Search ถึง Word ท้ายของประโยคSpeech Recognition เป็นเทคโนโลยีที่สามารถนำไปใช้ได้อย่างหลากหลาย อย่างเช่น ในอุตสาหกรรม Health Care ผู้ที่ใช้ประโยชน์จากเทคโนโลยีนี้คือ ฝ่าย admin และหมอ พยาบาล เภสัชกรที่ไม่ถนัดหรือไม่ชื่นชอบการพิมพ์, หรือแม้กระทั่งทางการทหาร ก็สามารถนำเทคโนโลยีนี้ไปใช้เพื่อสั่งการระบบนักบินอัตโนมัติ (Autopilot), ติดตั้งความถี่คลื่นวิทยุ หรือควบคุม flight display เป็นต้น นอกจากนี้ เทคโนโลยีนี้ยังสามารถนำไปใช้ประโยชน์อย่างอื่นได้อีก เช่น การแปลอัตโนมัติ, การสั่งการรถยนต์, การโทรสนเทศ(Telematics), การรายงานในศาล (Court reporting หรือ Real-time Voice Writing), คอมพิวเตอร์แฮนด์ฟรี, โทรศัพท์มือถือ, หุ่นยนต์, video games, Interactive Voice Response (IVR), Speech-to-text (การแปลเสียงให้เป็นคำพูด) และการควบคุมการจราจรทางอากาศ เป็นต้นในต่างประเทศ Application ที่นำเทคโนโลยีนี้ไปใช้กันอย่างค่อนข้างแพร่หลาย ได้แก่ โทรศัพท์ตอบรับอัตโนมัติ เช่น จองตั๋วเครื่องบิน สอบถามรอบฉายภาพยนตร์ หรือการสั่งการอุปกรณ์ไฟฟ้าต่าง ๆด้วยเสียง แต่ในประเทศไทย เนื่องจากยังไม่สามารถทำ recognizer ที่มีประสิทธิภาพดีเพียงพอที่จะนำมาใช้เชิงธุรกิจได้ จึงยังไม่มีการนำมาใช้มากเท่าใดนักกระบวนการในการรู้จำเสียง ขบวนการในการรู้จำเสียงโดยทั่วไปสามารถแบ่งออกเป็นส่วนต่าง ๆ ดังภาพ จะประกอบด้วยขั้นตอนการดำเนินงานหลัก 3 ขั้นตอนคือ ขั้นตอนการดำเนินงานของการรู้จำเสียง